

Dans le numéro 240 de CAD Magazine, Jean-Sebastien Gros – Partner en charge de l’offre Innovation, et Xavier Brucker – Managing Partners de notre lab Data Sciences & IA Mews Labs, analysent le potentiel de l’intelligence générative pour l’ingénierie.
L’IA générative, ou LLM (grand modèle de langage), est omniprésente dans l’actualité, et les cas d’usages potentiels alimentent l’imagination des ingénieurs sur l’ensemble de la chaîne de valeur. La R&D pourrait tirer énormément de valeur de cette technologie.
En théorie, la R&D, et en particulier l’ingénierie de développement produit, semble être un terrain de jeu naturel pour cette technologie. Par nature, il s’agit d’une activité collaborative qui produit de façon atomisée énormément de connaissances écrites plus ou moins formalisées. Or, le seul liant certain de l’ensemble de ces connaissances demeure le langage, précisément ce dont se nourrit le LLM.
Toutefois, une « compatibilité naturelle » ne suffit pas pour transformer une technologie en game changer métier. Mais le discours ambiant, centré sur l’absolue nécessité de prendre le train en marche, n’aide pas à se focaliser sur l’essentiel : il faut bien entendu partir de besoins concrets et déployer les bons choix technologiques en conséquence, puis itérer. En bref, il faut viser l’industrialisation et ne pas se disperser sur des projets vitrines.
Dès lors, revenons à l’essentiel : comment savoir si le LLM a un potentiel pour tel ou tel cas d’usage ? Quels sont les critères qui établissent cette pertinence et qui permettront de prioriser et, in fine, de définir une roadmap de projets LLM viables et industrialisables ?

CRITÈRE #1 : LA PERTINENCE DE LA DONNÉE DISPONIBLE
Le LLM est avant tout une histoire de données : il est aussi fort que les informations sur lesquelles il s’appuie. À cet égard, c’est avant tout la typologie (et la fiabilité) des données à disposition dans le cadre d’un cas d’usage qui va définir sa pertinence. Mais, surtout, sa force réside dans sa capacité à travailler avec des données non structurées. Ainsi, le LLM apportera assez peu de valeur ajoutée dans le cas où l’on chercherait un matériau spécifique dans une base de données structurées dont les attributs sont suffisamment détaillés.
En revanche, il saura parfaitement s’appuyer sur un corpus de documents disparates (fichier des non-qualité, documentation projet, normes…) pour identifier, par exemple, des solutions mises en œuvre par le passé afin de résoudre un problème présent spécifique, comme l’amélioration de la fiabilité d’un mécanisme.
CRITÈRE #2 : LA MATURITÉ DES PARTIES PRENANTES VIS-À-VIS DE L'OBJECTIF DU CAS D'USAGE
La pertinence du LLM n’est pas une question binaire. Dans certains cas, la valeur ajoutée pourra être transverse, générale, dans d’autres, le LLM ne sera utile que sur certaines étapes spécifiques d’une problématique métier.
Le rôle de l’utilisateur dans une problématique donnée, sa maturité vis-à-vis du sujet et le niveau de ses attentes en termes de précision (voir critère 4) sont particulièrement critiques. Moins un utilisateur est spécialiste et plus le niveau d’exigence est faible, plus le LLM va facilement apporter de la valeur ajoutée.
Prenons par exemple le sujet de la génération d’exigences. Une bonne part de l’enjeu repose sur des parties prenantes en aval, au niveau de l’industrialisation. À ce stade, les ingénieurs identifient et résolvent généralement un certain nombre de problématiques qu’il faudrait, dans l’idéal, formuler en exigences à faire remonter en phase de conception.
Mais la formulation d’exigences est un sujet peu ancré dans les réflexes des ingénieurs en industrialisation : cette phase est un maillon faible de la discipline. Dès lors, le LLM pourrait beaucoup apporter, ce d’autant plus que la formulation d’exigences s’appuie généralement sur un corpus documentaire peu structuré.

CRITÈRE #3 : L'ADÉQUATION DE L'OBJECTIF AVEC LES "FONCTIONNALITÉS" DU LLM
S’il ne faut pas développer de use case LLM en fonction de ce que la technologie propose mais bien à partir du besoin, il faut tout de même que ce dernier soit en adéquation avec ce que l’IA générative sait faire de mieux. Dans certains cas, l’objectif peut être rempli de façon extrêmement rapide, sans mise au point complémentaire ou développement spécifique. Certains besoins basiques et focalisés, comme la traduction, la production de résumés, sont des cas d’usage tout indiqués. On peut ainsi évoquer la production de volumes de formation, la formulation de documentation utilisateur…
En sollicitant des fonctionnalités plus avancées (contrôle de cohérence, avec des spécifications par exemple), il faudra potentiellement beaucoup de mise au point, voire des développements spécifiques mélangeant au LLM d’autres technologies.
CRITÈRE #4 : LE NIVEAU DE PRÉCISION ATTENDU
Corollaire du critère précédent, le degré de précision espéré de la part du LLM sera central dans l’évaluation de la pertinence du cas d’usage. Là encore, dans la plupart des cas, plus il progresse en criticité, moins le LLM est capable d’apporter le niveau de précision espéré. Autrement dit, la technologie se prête à la production de documents de formation ou d’awareness, là où sa capacité à résumer ou à reformuler fait des merveilles. En revanche, il ne paraît pas envisageable de lui faire produire sans assistance des documents de maintenance, là où les conséquences d’une imprécision sont majeures.
Il conviendra alors d’accompagner l’utilisation du LLM d’un contrôle qualité rigoureux par un utilisateur expert… à mettre en balance, encore une fois, avec la valeur ajoutée du use case.
CRITÈRE #5 : LE DEGRÉ DE COMPLEXITÉ
La complexité du cas d’usage se mesure notamment au nombre et à la diversité de ses étapes, ou encore au degré de standardisation de son processus. On peut ainsi classer la création d’un modèle système — qui implique pour chacun des niveaux d’architecture un travail de définition des éléments et des flux qui les lient — ou encore la définition d’un plan d’intégration vérification validation au rang de cas d’usage complexes.
Cette complexité va amener à la reproduction de la même mécanique que l’on devine maintenant : plus elle est croissante, plus cela impliquera des efforts supplémentaires, plus la valeur ajoutée doit être nette pour valoir le coup.
CONCLUSION
Pour respecter ces six critères, il apparaît vite que le LLM doit être adapté : passée la phase de « quick wins », des développements spécifiques seront requis… qui devront valoir le coup.
In fine, il s’agit donc davantage de prioriser les besoins et donc les use cases en fonction de la vitesse et de la facilité avec laquelle le LLM va apporter de la valeur que de distinguer ceux pour lesquels cette technologie apporte quelque chose de ceux pour lesquels elle n’apporte rien.
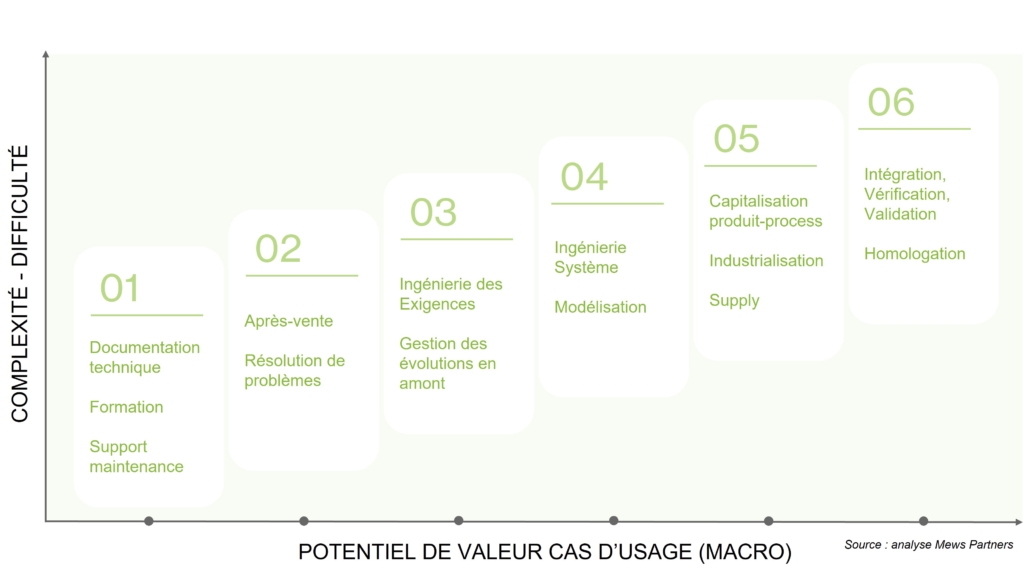
Schématisation du quick-win aux cas les plus complexes






")

